財經中心/師瑞德報導
 鴻海研究院與香港城市大學合作開發的 ModeSeq模型,在國際自駕技術大賽中奪冠。這套多模態軌跡預測技術能同時模擬車輛與行人的多種可能走向,幫助自駕系統提前做出判斷,大幅提升行車安全,讓AI更接近「秒懂」人類行為的未來。(圖/鴻海研究院提供)
鴻海研究院與香港城市大學合作開發的 ModeSeq模型,在國際自駕技術大賽中奪冠。這套多模態軌跡預測技術能同時模擬車輛與行人的多種可能走向,幫助自駕系統提前做出判斷,大幅提升行車安全,讓AI更接近「秒懂」人類行為的未來。(圖/鴻海研究院提供)你有想過嗎?我們走在馬路上時,總希望能預測別人下一步要幹嘛。比如前面行人會不會突然過馬路?隔壁車道的車會不會硬切進來?這些瞬間的判斷,對人類駕駛來說靠的是經驗與直覺,但對自駕車來說,這卻是生死攸關的難題。要是算錯一步,可能就發生事故。現在,台灣鴻海研究院帶來了一個答案。
鴻海研究院與香港城市大學合作的多模態軌跡預測模型「ModeSeq」,最近在全球最頂尖的人工智慧會議 CVPR 2025(Computer Vision and Pattern Recognition Conference,電腦視覺與圖形辨識會議)發表,並進一步優化成「Parallel ModeSeq」後,參加Waymo Open Dataset (WOD) Interaction Prediction Challenge,奪下冠軍。這場比賽吸引了新加坡國立大學、喬治亞理工學院、不列顛哥倫比亞大學等世界級隊伍,最後由來自台灣的鴻海拔得頭籌。
這不只是科研界的獎盃,對你我來說,這意味著未來的自駕車,更有能力「看穿」人車的走向,提前做出判斷,避免危險。聽起來像是科幻電影,但事實上正在真實上演。
什麼是多模態軌跡預測?
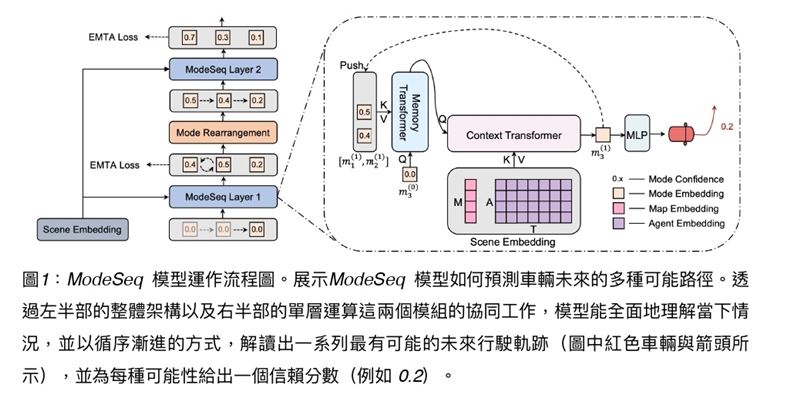
簡單來說,多模態軌跡預測(Multimodal Trajectory Prediction)就是一種AI技術,能預測道路上人或車未來可能的多種行為。
傳統的模型大多只能給出「一條最可能的路徑」,比如判斷前車會直行。但現實生活遠比這複雜:一輛車在路口可能左轉、右轉、或臨時停下;行人可能快步穿越,也可能臨時退回。這些都是不同的「模態」(模式)。
ModeSeq 的厲害之處在於,它不只會告訴你「最有可能發生什麼」,還能同時給出多種可能性,並附上機率。例如:80% 會直行、15% 會左轉、5% 會右轉。這樣一來,自駕車系統就能「多備幾手」,提早準備。
 鴻海研究院與香港城市大學合作開發的 ModeSeq模型,在國際自駕技術大賽中奪冠。這套多模態軌跡預測技術能同時模擬車輛與行人的多種可能走向,幫助自駕系統提前做出判斷,大幅提升行車安全,讓AI更接近「秒懂」人類行為的未來。(圖/鴻海研究院提供)
鴻海研究院與香港城市大學合作開發的 ModeSeq模型,在國際自駕技術大賽中奪冠。這套多模態軌跡預測技術能同時模擬車輛與行人的多種可能走向,幫助自駕系統提前做出判斷,大幅提升行車安全,讓AI更接近「秒懂」人類行為的未來。(圖/鴻海研究院提供)為什麼這很重要?
你可以想像,一台自駕車如果只相信單一路徑,一旦判斷錯誤就會失敗。但如果它同時準備了好幾個劇本,就能隨時調整反應。這對行車安全有極大幫助。
根據 Waymo 提供的資料,交通事故中有超過三成發生在「交互場景」,也就是車與車、車與行人互相影響的狀況。這也是 WOD 挑戰賽特別強調的地方,要求參賽隊伍能預測兩個交通參與者在8秒內的互動行為。鴻海的Parallel ModeSeq,就是在這樣的高難度情境下脫穎而出。
鴻海研究院人工智慧研究所所長栗永徽解釋,ModeSeq 能在保持高準確度的同時,降低運算成本,讓系統可以「又快又準」地完成判斷。更重要的是,它還具備「模態外推(Mode Extrapolation)」的能力,也就是能根據場景不確定性,動態決定要預測幾種行為模式。這代表在簡單場景中,模型不會浪費資源計算太多路徑;但在複雜場景中,它又能拉出更多可能性,全面覆蓋風險。
 鴻海研究院與香港城市大學合作開發的 ModeSeq模型,在國際自駕技術大賽中奪冠。這套多模態軌跡預測技術能同時模擬車輛與行人的多種可能走向,幫助自駕系統提前做出判斷,大幅提升行車安全,讓AI更接近「秒懂」人類行為的未來。(圖/鴻海研究院提供)
鴻海研究院與香港城市大學合作開發的 ModeSeq模型,在國際自駕技術大賽中奪冠。這套多模態軌跡預測技術能同時模擬車輛與行人的多種可能走向,幫助自駕系統提前做出判斷,大幅提升行車安全,讓AI更接近「秒懂」人類行為的未來。(圖/鴻海研究院提供)國際舞台的勝利
CVPR(Computer Vision and Pattern Recognition Conference)被譽為電腦視覺領域的「奧運會」。每年吸引 Google、Meta、NVIDIA 等科技巨頭,以及頂尖學術機構參與。
鴻海研究院團隊今年6月13日在會議上正式發表ModeSeq技術,隨後推出改良版Parallel ModeSeq參賽,最終擊敗眾多強敵奪冠。這已經是鴻海研究院連續第二年在 CVPR 相關比賽中拿下獎項,去年 ModeSeq 曾在「Waymo Motion Prediction Challenge」拿下全球第二名。
這樣的成績不只展現鴻海的研發實力,也讓世界看見台灣在自駕 AI 領域的競爭力。
科技背後的科普:怎麼做到的?
ModeSeq 的核心是利用因式分解變換器(Factorized Transformers)做場景編碼,理解整個環境資訊,接著再透過特製的ModeSeq 層進行解碼。這一層同時結合了記憶模組與變換器,讓模型能夠逐步「推演」出一條又一條合理的軌跡。
此外,研究團隊還設計了一種新的損失函數,叫做Early-Match-Take-All (EMTA)。傳統模型在訓練時,很容易只專注於「平均誤差最小」的結果,導致缺乏多樣性。而 EMTA 的設計,能引導模型更早識別多種可能性,避免「一條路走到黑」。
最終成果在各項評測上都很亮眼:不僅在mAP(mean Average Precision,平均精確率)與 soft mAP指標上超越同類方法,在 minADE(平均距離誤差) 與 minFDE(最終距離誤差)上也保持頂尖水準。
從比賽走進生活
對一般人來說,這些技術名詞或許有點抽象。但可以換個方式想:這就像是一個超強的「交通占卜師」,能在瞬間推演出所有可能的劇本,並告訴你哪一個最有可能發生。
未來,當這套技術被應用在自駕車裡,乘客不必再擔心「這台車能不能及時反應?」因為 AI 已經提前考慮過所有劇本,甚至包括低機率但高風險的狀況。
這樣的技術不只適用於自駕車,也能拓展到智慧交通管理、人群安全監控,甚至是服務型機器人在人群中移動時的避障。可以說,它是一個核心拼圖,幫助 AI 更懂「人類的行為模式」。
鴻海的野心與未來
鴻海研究院自2020年成立以來,旗下設有五大研究所與一間實驗室,專注於未來三到七年的前瞻技術。此次 ModeSeq 的突破,不僅是研究成果,更是鴻海「智慧導向」轉型的一部分。
透過AI技術的積累,鴻海不僅強化了自家在自駕產業的佈局,也為全球市場提供更高安全性與可靠性的解決方案。這不只是科研的榮耀,更可能影響未來每一位搭上自駕車的乘客。
栗永徽所長強調:「能在 CVPR 這樣的國際舞台上被收錄與肯定,證明我們的研究已達世界頂尖水準。這套技術未來會繼續優化,並推廣到更多實際應用場景,帶來更安全、更高效的智慧交通體驗。」









 5 顆
5 顆  10 顆
10 顆  15 顆
15 顆  20 顆
20 顆